科普一下:进程与线程
1、进程与线程
进程:是程序的一次执行过程,是系统进行资源调度和分配的基本单位,实现了操作系统内部的并发。
线程:一个进程在执行的过程中可以产生多个线程,是CPU调度和分派的基本单位,实现了进程内部的并发。
二者的主要区别:
根本区别:
进程是操作系统资源分配的基本单位;
线程是处理器任务调度和执行的基本单位。
资源开销:
每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;
线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
包含关系:
如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)并行完成的;
线程是进程的一部分,所以线程也被称为轻量级进程。
内存分配:
同一进程的线程共享本进程的地址空间和资源;
进程之间的地址空间和资源是相互独立的。
影响关系:
一个进程崩溃后,在保护模式下不会对其他进程产生影响;
但是一个线程崩溃整个进程都死掉,所以多进程要比多线程健壮。
执行过程:
每个独立的进程有程序运行的入口、顺序执行序列和程序出口;
但是线程不能独立执行,线程依赖应用程序(进程),由应用程序控制多个线程的执行过程;
两者均可并发执行。
2、线程的 5 种状态
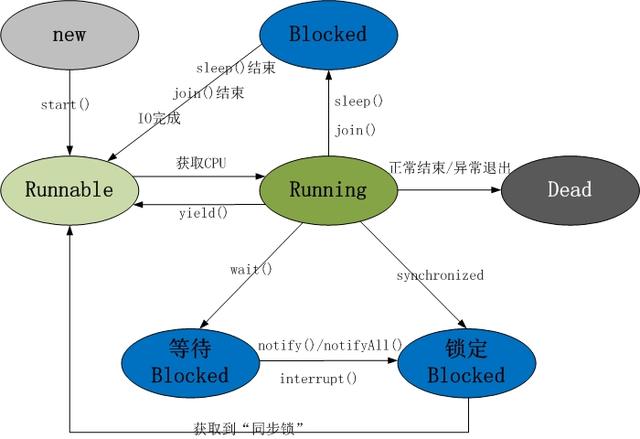
1)新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
2)就绪状态(Runnable):当调用线程对象的start()方法,线程即进入就绪状态;处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start() 此线程立即就会执行。
3)运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
4)阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 — 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 — 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时. join()等待线程终止或者超时. 或者I/O处理完毕 时,线程重新转入就绪状态。
5)死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
3、为什么要使用多线程?
- 从计算机底层原理来说: 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
- 从互联网发展趋势来说: 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以。
再从计算机底层展开来说:
- 单核时代:在单核时代多线程主要是为了提高 CPU 和 IO 设备的综合利用率。举个例子:当只有一个线程的时候会导致 CPU 计算时,IO 设备空闲;进行 IO 操作时,CPU 空闲。我们可以简单地说这两者的利用率目前都是 50%左右。但是当有两个线程的时候就不一样了,当一个线程执行 CPU 计算时,另外一个线程可以进行 IO 操作,这样两个的利用率就可以在理想情况下达到 100%了。
- 多核时代:多核时代多线程主要是为了提高 CPU 利用率。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,CPU 只会一个 CPU 核心被利用到,而创建多个线程就可以让多个 CPU 核心被利用到,这样就提高了 CPU 的利用率。
4、并发与并行的区别?
并发: 同一时段内,多个任务都在执行(强调一段时间)
并行: 单位时间内,多个任务同时执行(强调同一时刻)
5、使用多线程可能带来什么问题?
并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
6、什么是上下文切换?
线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的运行栈、程序计数器等。
当出现如下情况的时候,线程会从占用 CPU 状态中退出:
- 主动让出 CPU,比如调用了
sleep(),wait()等。 - 时间片用完,因为操作系统要防止一个线程或者进程长时间占用CPU导致其他线程或者进程饿死。
- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞。
- 被终止或结束运行
这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,等待线程下次占用 CPU 的时候恢复现场,并加载下一个将要占用 CPU 的线程上下文。这就是所谓的 上下文切换!
上下文切换是现代操作系统的基本功能,因其每次需要保存信息、恢复信息,这将会占用 CPU、内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下!
7、什么是线程死锁?
7.1 线程死锁
线程死锁:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放,形成了相互等到的情况。因此线程被无限期地阻塞,并且程序不可能正常终止,这就是线程死锁。
如下图,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
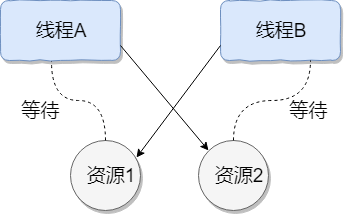
下面通过一个例子来说明线程死锁,代码模拟了上图的死锁的情况 (代码来源于《并发编程之美》):
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
Output
Thread[线程 1,5,main]get resource1
Thread[线程 2,5,main]get resource2
Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。
线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
上例符合产生死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
7.2 如何预防和避免死锁?
如何预防死锁? (理论)
破坏死锁的产生的必要条件即可:
- 破坏请求与保持条件 :一次性申请所有的资源。
- 破坏不剥夺条件 :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件 :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
如何避免死锁?(实践)
避免死锁就是在资源分配时,借助算法(比如银行家算法)对资源分配进行评估,使其进入安全状态。
所谓安全状态,是指系统能按某种进程推进顺序( P1, P2, …, Pn),为每个进程Pi分配其所需资源,直至满足每个进程对资源的最大需求,使每个进程都可顺序地完成。此时称 P1, P2, …, Pn 为安全序列。如果系统无法找到一个安全序列,则称系统处于不安全状态。
当然,并非所有的不安全状态都是死锁状态,但当系统进入不安全状态后,便可能进入死锁状态;反之,只要系统处于安全状态,系统便可以避免进入死锁状态。
我们对线程 2 的代码稍作修改就不会产生死锁了:
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 2").start();
Output
Thread[线程 1,5,main]get resource1
Thread[线程 1,5,main]waiting get resource2
Thread[线程 1,5,main]get resource2
Thread[线程 2,5,main]get resource1
Thread[线程 2,5,main]waiting get resource2
Thread[线程 2,5,main]get resource2
Process finished with exit code 0
我们分析一下上面的代码为什么避免了发生死锁?
线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了resource1;
然后线程 1 再去获取 resource2 的监视器锁,可以获取到;
然后线程 1 执行完毕后释放了对 resource1、resource2 的占用;
线程 2 就可以获取到resource1、resource2 了。
这样就破坏了破坏循环等待条件,因此避免了死锁的发生!
8、说说 sleep() 方法和 wait() 的异同点?
相同点:
两者都可以暂停正在执行的线程!
两者区别:
- 两者最主要的区别在于:
sleep()方法没有释放锁;wait()方法释放了锁 wait()通常被用于线程间交互/通信;sleep()通常被用于暂停执行wait()是Object的方法,必须与synchronized关键字一起使用;sleep()是Thread类的静态方法wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll()方法;sleep()方法执行完成后,线程会自动苏醒
9、为什么调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
当new 一个 Thread,线程进入了新建状态,调用 start()方法后,会启动该线程并进入就绪状态,当分配到时间片后就可以开始运行了。
start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。
但是,直接调用 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会开启一个新线程去执行它,所以这并不是多线程工作。
总结: 调用 start() 方法方可启动线程并使其进入就绪状态,而直接调用 run() 方法的话不会以多线程的方式执行!
10、Thread类中的yield方法有什么作用?
Thread.yield() 方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。
它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂停状态后马上又被执行。
11、创建线程的3种方式?
1)实现Runnable接口,实现run方法
public class RunnableTest implements Runnable {
private int i;
public void run() {
for (i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 20) {
RunnableTest rtt = new RunnableTest();
new Thread(rtt, "新线程1").start();
new Thread(rtt, "新线程2").start();
}
}
}
}
2)实现Callable接口,实现call方法
public class CallableTest implements Callable<Integer> {
public static void main(String[] args) {
CallableTest ctt = new CallableTest();
FutureTask<Integer> ft = new FutureTask<>(ctt);
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " 的循环变量i的值" + i);
if (i == 20) {
new Thread(ft, "有返回值的线程").start();
}
}
try {
System.out.println("子线程的返回值:" + ft.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
@Override
public Integer call() throws Exception {
int i = 0;
for (; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
return i;
}
}
3)继承Thread类,重写run方法
public class ThreadTest extends Thread {
int i = 0;
//重写run方法,run方法的方法体就是现场执行体
public void run() {
for (; i < 100; i++) {
System.out.println(getName() + " " + i);
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " : " + i);
if (i == 20) {
new ThreadTest().start();
new ThreadTest().start();
}
}
}
}
Runnable和Callable的区别
Callable的任务执行后可返回值,而Runnable的任务是不能返回值的。
Call方法可以抛出异常,run方法不可以。
运行Callable任务可以拿到一个Future对象,表示异步计算的结果;
它提供了检查计算是否完成的方法,以等待计算的完成,并检索算的结果;
通过Future对象可以了解任务执行情况,可取消任务的执行,还可获取执行结果。